资料中包含下列文件,点击文件名可预览资料内容













还剩43页未读,
继续阅读
所属成套资源:高中数学人教A版选择性必修第三册课件+教案+导学案+练习
成套系列资料,整套一键下载
2020-2021学年8.2 一元线性回归模型及其应用评优课ppt课件
展开
这是一份2020-2021学年8.2 一元线性回归模型及其应用评优课ppt课件,文件包含82一元线性回归模型及其应用课件-人教A版选择性必修第三册pptx、82一元线性回归模型及其应用教学设计-人教A版选择性必修第三册docx、82一元线性回归模型及其应用导学案-人教A版选择性必修第三册docx等3份课件配套教学资源,其中PPT共51页, 欢迎下载使用。
1.能通过具体实例说明一元线性回归模型修改的依据与方法.2.通过对具体问题的进一步分析,能将某些非线性回归问题转化为线 性回归问题并加以解决,提高数学运算能力.3.能通过实例说明决定系数R2的意义和作用,提高数据分析能力。
通过前面的学习我们已经了解到,根据成对样本数据的散点图和样本相关系数,可以推断两个变量是否存在相关关系、是正相关还是负相关,以及线性相关程度的强弱等. 如果能像建立函数模型刻画两个变量之间的确定性关系那样,通过建立适当的统计模型刻画两个随机变量的相关关系,那么我们就可以利用这个模型研究两个变量之间的随机关系,并通过模型进行预测.
探究1:生活经验告诉我们,儿子的身高与父亲的身高相关.一般来说,父亲的身高较高时,儿子的身高通常也较高.为了进一步研究两者之间的关系,有人调查了14名男大学生的身高及其父亲的身高,得到的数据如表所示.
可以发现,散点大致分布在一条从左下角到右上角的直线附近,表明儿子身高和父亲身高线性相关.利用统计软件,求得样本相关系数为r≈0.886,表明儿子身高和父亲身高正线性相关,且相关程度较高。
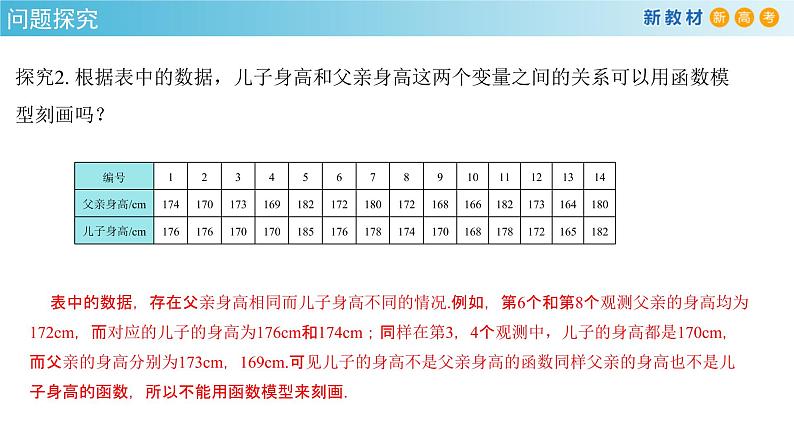
探究2. 根据表中的数据,儿子身高和父亲身高这两个变量之间的关系可以用函数模型刻画吗?
表中的数据,存在父亲身高相同而儿子身高不同的情况.例如,第6个和第8个观测父亲的身高均为172cm,而对应的儿子的身高为176cm和174cm;同样在第3,4个观测中,儿子的身高都是170cm,而父亲的身高分别为173cm,169cm.可见儿子的身高不是父亲身高的函数同样父亲的身高也不是儿子身高的函数,所以不能用函数模型来刻画.
探究3:从成对样本数据的散点图和样本相关系数可以发现,散点大致分布在一条直线附近表明儿子身高和父亲身高有较强的线性关系.我们可以这样理解,由于有其他因素的存在,使儿子身高和父亲身高有关系但不是函数关系.那么影响儿子身高的其他因素是什么?
影响儿子身高的因素除父亲的身外,还有母亲的身高、生活的环境、饮食习惯、营养水平、体育锻炼等随机的因素,儿子身高是父亲身高的函数的原因是存在这些随机的因素.
探究3:由探究3我们知道,正是因为存在这些随机的因素,使得儿子的身高呈现出随机性各种随机因素都是独立的,有些因素又无法量化.你能否考虑到这些随机因素的作用,用类似于函数的表达式,表示儿子身高与父亲身高的关系吗?
如果用x表示父亲身高,Y表示儿子的身高,用e表示各种其他随机因素影响之和,称e为随机误差,由于儿子身高与父亲身高线性相关,所以Y=bx+a.
其中,Y称为因变量或响应变量,x称为自变量或解释变量;a和b为模型的未知参数,a称为截距参数,b称为斜率参数;e是Y与bx+a之间的随机误差,模型中的Y也是随机变量,其值虽然不能由变量x的值确定,但是却能表示为bx+a与e的和(叠加),前一部分由x所确定,后一部分是随机的,如果e=0,那么Y与x之间的关系就可用一元线性函数模型来描述.
问题1. 你能结合父亲与儿子身高的实例,说明回归模型①的意义?
问题2.你能结合具体实例解释产生模型①中随机误差项的原因吗?
产生随机误差e的原因有:(1)除父亲身高外,其他可能影响儿子身高的因素,比如母亲身高、生活环境、饮食习惯和锻炼时间等.(2)在测量儿子身高时,由于测量工具、测量精度所产生的测量误差.(3)实际问题中,我们不知道儿子身高和父亲身高的相关关系是什么,可以利用一元线性回归模型来近似这种关系,这种近似关系也是产生随机误差e的原因.
与函数模型不同,回归模型的参数一般是无法精确求出的,只能通过成对样本数据估计这两个参数。参数a和b刻画了变量Y与变量x的线性关系,因此通过样本数据估计这两个参数,相当于寻找一条适当的直线,使表示成对样本数据的这些散点在整体上与这条直线最接近.
问题4.我们怎样寻找一条“最好”的直线,使得表示成对样本数据的这些散点在整体上与这条直线最“接近”?
目标:从成对样本数据出发,用数学的方法刻画“从整体上看,各散点与直线最接近”方法:利用点到直线y=bx+a的“距离”来刻画散点与该直线的接近程度,然后用所有“距离”之和刻画所有样本观测数据与该直线的接近程度.
我们设满足一元线性回归模型的两个变量的n对样本数据为(x1,y1),(x2,y2),…,(xn,yn),由yi=bxi+a+ei(i=1,2,…,n),得|yi-(bxi+a)|=|ei|.显然|ei|越小,表示点(xi,yi)与点(xi,bxi+a)的“距离”越小,即样本数据点离直线y=bx+a的竖直距离越小。特别地,当ei=0时,表示点(xi,yi)在这条直线上.
在实际应用中,因为绝对值使得计算不方便,所以人们通常用各散点到直线的竖直距离的平方之和
求a,b的值,使Q(a,b)最小
上式是关于b的二次函数,因此要使Q取得最小值,当且仅当b的取值为
我们将 称为Y关于x的经验回归方程,也称经验回归函数或经验回归公式,其图形称为经验回归直线,这种求经验回归方程的方法叫最小二乘法.
问题5:利用下表的数据,依据用最小二乘估计一元线性回归模型参数的公式,求出儿子身高Y关于父亲身高x的经验回归方程。
问题6:当x=176时, ,如果一位父亲身高为176cm,他儿子长大后身高一定能长到177cm吗?为什么?
例如,对于右表中的第6个观测,父亲身高为172cm,其儿子身高的观测值为y==176(cm),预测值为96=0.839×172+28.957=173.265(cm),残差为176-173.265=2.735(cm).类似地,可以得到其他的残差,如右表所示.
问题7:儿子身高与父亲身高的关系,运用残差分析所得的一元线性回归模型的有效性吗?
残差图:作图时纵坐标 为残差,横坐标可以选为样本编号,或身高数据,或体重估计值等,这样作出的图形称为残差图.
观察表可以看到,残差有正有负,残差的绝对值最大是4.413.观察残差的散点图可以发现,残差比较均匀地分布在横轴的两边,说明残差比较符合一元线性回归模型的假定,是均值为0、方差为σ2的随机变量的观测值.可见,通过观察残差图可以直观判新模型是否满足一元线性回归模型的假设. 一般地,建立经验回归方程后,通常需要对模型刻画数据的效果进行分析,借助残差分析还可以对模型进行改进,使我们能根据改进模型作出更符合实际的预测与决策。
问题8:观察以下四幅残差图,你认为哪一个残差满足一元线性回归模型中对随机误差的假定?
所以,只有图(4)满足一元线性回归模型对随机误差的假设。
例1.经验表明,对于同一树种,一般树的胸径(树的主干在地面以上1.3m处的直径)越大,树就越高.由于测量树高比测量胸径困难,因此研究人员希望由胸径预测树高.在研究树高与胸径之间的关系时,某林场收集了某种树的一些数据如下表所示,试根据这些数据建立树高关于胸径的经验回归方程.
解: 以胸径为横坐标,树高为纵坐标作散点图如下:
散点大致分布在一条从左下角到右上角的直线附近,表明两个变量线性相关,并且是正相关,因此可以用一元线性回归模型刻画树高与胸径之间的关系.用d表示胸径,h表示树高,根据据最小二乘法,计算可得经验回归方程为
根据经验回归方程,由胸径的数据可以计算出树高的预测值(精确到0.1)以及相应的残差,如下表所示.
以胸径为横坐标,残差为纵坐标,作残差图,得到下图.
观察残差表和残差图,可以看到残差的绝对值最大是 0.8,所有残差分布在以横轴为对称轴、宽度小于2的带状区域内 .可见经验回归方程较好地刻画了树高与胸径的关系,我们可以根据经验回归方程由胸径预测树高.
(1)确定研究对象,明确哪个变量是解释变量,哪个变量是响应变量.(2)画出解释变量与响应变量的散点图,观察它们之间的关系 (如是否存在线性关系等).(3)由经验确定回归方程的类型.(4)按一定规则(如最小二乘法)估计经验回归方程中的参数.(5)得出结果后需进行线性回归分析.①残差平方和越小,模型的拟合效果越好.②决定系数R2取值越大,说明模型的拟合效果越好.需要注意的是:若题中给出了检验回归方程是否理想的条件,则根据题意进行分析检验即可.
建立线性回归模型的基本步骤:
例2.人们常将男子短跑100m的高水平运动员称为“百米飞人”.下表给出了1968年之前男子短跑100m世界纪录产生的年份和世界纪录的数据.试依据这些成对数据,建立男子短跑100m世界纪录关于纪录产生年份的经验回归方程。
解:以成对数据中的世界纪录产生年份为横坐标,世界纪录为纵坐标作散点图,得到下图,散点看上去大致分布在一条直线附近,似乎可用一元线性回归模型建立经验回归方程.用Y表示男子短跑100m的世界纪录,t表示纪录产生的年份 ,利用一元线性回归模型来刻画世界纪录和世界纪录产生年份之间的关系 . 根据最小二乘法,由表中的数据得到经验回归方程为:
将经验回归直线叠加到散点图,得到下图:
仔细观察:从图中可以看到,经验回归方程较好地刻画了散点的变化趋势,请再仔细观察图形,你能看出其中存在的问题吗? 第一个世界纪录所对应的散点远离经验回归直线,并且前后两时间段中的散点都在经验回归直线的上方,中间时间段的散点都在经验回归直线的下方. 这说明散点并不是随机分布在经验回归直线的周围, 而是围绕着经验回归直线有一定的变化规律, 即成对样本数据呈现出明显的非线性相关的特征.
思考:你能对模型进行修改,以使其更好地反映散点的分布特征吗?
仔细观察,可以发现散点更趋向于落在中间下凸且递减的某条曲线附近.回顾已有的函数知识,可以发现函数y=-lnx的图象具有类似的形状特征 注意到100m短跑的第一个世界纪录产生于1896年, 因此可以认为散点是集中在曲线y=f(t)=c1+c2ln(t-1895)的周围,其中c1、c2为未知参数,且c2<0. 用上述函数刻画数据变化的趋势,这是一个非线性经验回归函数,其中c1,c2是待定参数,现在问题转化为如何利用成对数据估计参数c1和c2
令x=ln(t-1895),则 Y=c2x+c1对数据进行变化可得下表:
得到散点图,由表中的数据得到经验回归方程为:
上图表明,经验回归方程对于成对数据具有非常好的拟合精度.将x=ln(t-1895)代入:
对于通过创纪录时间预报世界纪录的问题,我们建立了两个回归模型,得到了两个回归方程,你能判断哪个回归方程拟合的精度更好吗?
我们发现,散点图中各散点都非常靠近②的图象, 表明非线性经验回归方程②对于原始数据的拟合效果远远好于经验回归方程①.
(1).直接观察法.在同一坐标系中画出成对数据散点图、非线性经验回归方程②的图象(蓝色)以及经验回归方程①的图象(红色).
(2).残差分析:残差平方和越小,模型拟合效果越好.
Q2明显小于Q1,说明非线性回归方程的拟合效果要优于线性回归方程.
(3).利用决定系数R2刻画回归效果.
R2越大,表示残差平方和越小,即模型的拟合效果越好R2越小,表示残差平方和越大,即模型拟合效果越差.①和②的R2分别为0.7325和0.9983说明非线性回归方程的拟合效果要优于线性回归方程。
(4)用新的观测数据来检验模型的拟合效果,事实上,我们还有1968年之后的男子短跑100m世界纪录数据,如表所示
在散点图中,绘制表中的散点(绿色),再添加经验回归方程①所对应的经验回归直线(红色),以及经验回归方程②所对应的经验回归曲线(蓝色),得到右图.显然绿色散点分布在蓝色经验回归曲线的附近,远离红色经验回归直线,表明经验回归方程②对于新数据的预报效果远远好于①.
思考:在上述问题情境中,男子短跑100m世界纪录和纪录创建年份之间呈现出对数关系,能借助于样本相关系数刻画这种关系的强弱吗?
在使用经验回归方程进行预测时,需要注意下列问题:(1)经验回归方程只适用于所研究的样本的总体,例如,根据我国父亲身高与儿子身高的数据建立的经验回归方程,不能用来描述美国父亲身高与儿子身高之间的关系,同样,根据生长在南方多雨地区的树高与胸径的数据建立的经验回归方程,不能用来描述北方干早地区的树高与胸径之间的关系。(2)经验回归方程一般都有时效性,例如,根据20世纪80年代的父亲身高与儿子身高的数据建立的经验回归方程,不能用来描述现在的父亲身高与儿子身高之间的关系。(3)解释变量的取值不能离样本数据的范围太远,一般解释变量的取值在样本数据范围内,经验回归方程的预报效果会比较好,超出这个范围越远,预报的效果越差,(4)不能期望经验回归方程得到的预报值就是响应变量的精确值,事实上,它是响应变量的可能取值的平均值。
建立非线性经验回归模型的基本步骤:
1.确定研究对象,明确哪个是解释变量,哪个是响应变量;2.由经验确定非线性经验回归方程的模型;3.通过变换,将非线性经验回归模型转化为线性经验回归模型;4.按照公式计算经验回归方程中的参数,得到经验回归方程;5.消去新元,得到非线性经验回归方程;6.得出结果后分析残差图是否有异常 .
跟踪训练1.一只药用昆虫的产卵数y与一定范围内的温度x有关,现收集了6组观测数据列于表中:
线性回归残差的平方和:
其中 分别为观测数据中的温度和产卵数,i=1,2,3,4,5,6.
(1)若用线性回归模型拟合,求y关于x的回归方程 (精确到0.1);
(2)若用非线性回归模型拟合,求得y关于x回归方程为且相关指数R2=0.9522.
①试与(1)中的线性回归模型相比较,用R2说明哪种模型的拟合效果更好 ?②用拟合效果好的模型预测温度为35℃时该种药用昆虫的产卵数.(结果取整数). 附:相关系数
∵0.9398<0.9522
1.能通过具体实例说明一元线性回归模型修改的依据与方法.2.通过对具体问题的进一步分析,能将某些非线性回归问题转化为线 性回归问题并加以解决,提高数学运算能力.3.能通过实例说明决定系数R2的意义和作用,提高数据分析能力。
通过前面的学习我们已经了解到,根据成对样本数据的散点图和样本相关系数,可以推断两个变量是否存在相关关系、是正相关还是负相关,以及线性相关程度的强弱等. 如果能像建立函数模型刻画两个变量之间的确定性关系那样,通过建立适当的统计模型刻画两个随机变量的相关关系,那么我们就可以利用这个模型研究两个变量之间的随机关系,并通过模型进行预测.
探究1:生活经验告诉我们,儿子的身高与父亲的身高相关.一般来说,父亲的身高较高时,儿子的身高通常也较高.为了进一步研究两者之间的关系,有人调查了14名男大学生的身高及其父亲的身高,得到的数据如表所示.
可以发现,散点大致分布在一条从左下角到右上角的直线附近,表明儿子身高和父亲身高线性相关.利用统计软件,求得样本相关系数为r≈0.886,表明儿子身高和父亲身高正线性相关,且相关程度较高。
探究2. 根据表中的数据,儿子身高和父亲身高这两个变量之间的关系可以用函数模型刻画吗?
表中的数据,存在父亲身高相同而儿子身高不同的情况.例如,第6个和第8个观测父亲的身高均为172cm,而对应的儿子的身高为176cm和174cm;同样在第3,4个观测中,儿子的身高都是170cm,而父亲的身高分别为173cm,169cm.可见儿子的身高不是父亲身高的函数同样父亲的身高也不是儿子身高的函数,所以不能用函数模型来刻画.
探究3:从成对样本数据的散点图和样本相关系数可以发现,散点大致分布在一条直线附近表明儿子身高和父亲身高有较强的线性关系.我们可以这样理解,由于有其他因素的存在,使儿子身高和父亲身高有关系但不是函数关系.那么影响儿子身高的其他因素是什么?
影响儿子身高的因素除父亲的身外,还有母亲的身高、生活的环境、饮食习惯、营养水平、体育锻炼等随机的因素,儿子身高是父亲身高的函数的原因是存在这些随机的因素.
探究3:由探究3我们知道,正是因为存在这些随机的因素,使得儿子的身高呈现出随机性各种随机因素都是独立的,有些因素又无法量化.你能否考虑到这些随机因素的作用,用类似于函数的表达式,表示儿子身高与父亲身高的关系吗?
如果用x表示父亲身高,Y表示儿子的身高,用e表示各种其他随机因素影响之和,称e为随机误差,由于儿子身高与父亲身高线性相关,所以Y=bx+a.
其中,Y称为因变量或响应变量,x称为自变量或解释变量;a和b为模型的未知参数,a称为截距参数,b称为斜率参数;e是Y与bx+a之间的随机误差,模型中的Y也是随机变量,其值虽然不能由变量x的值确定,但是却能表示为bx+a与e的和(叠加),前一部分由x所确定,后一部分是随机的,如果e=0,那么Y与x之间的关系就可用一元线性函数模型来描述.
问题1. 你能结合父亲与儿子身高的实例,说明回归模型①的意义?
问题2.你能结合具体实例解释产生模型①中随机误差项的原因吗?
产生随机误差e的原因有:(1)除父亲身高外,其他可能影响儿子身高的因素,比如母亲身高、生活环境、饮食习惯和锻炼时间等.(2)在测量儿子身高时,由于测量工具、测量精度所产生的测量误差.(3)实际问题中,我们不知道儿子身高和父亲身高的相关关系是什么,可以利用一元线性回归模型来近似这种关系,这种近似关系也是产生随机误差e的原因.
与函数模型不同,回归模型的参数一般是无法精确求出的,只能通过成对样本数据估计这两个参数。参数a和b刻画了变量Y与变量x的线性关系,因此通过样本数据估计这两个参数,相当于寻找一条适当的直线,使表示成对样本数据的这些散点在整体上与这条直线最接近.
问题4.我们怎样寻找一条“最好”的直线,使得表示成对样本数据的这些散点在整体上与这条直线最“接近”?
目标:从成对样本数据出发,用数学的方法刻画“从整体上看,各散点与直线最接近”方法:利用点到直线y=bx+a的“距离”来刻画散点与该直线的接近程度,然后用所有“距离”之和刻画所有样本观测数据与该直线的接近程度.
我们设满足一元线性回归模型的两个变量的n对样本数据为(x1,y1),(x2,y2),…,(xn,yn),由yi=bxi+a+ei(i=1,2,…,n),得|yi-(bxi+a)|=|ei|.显然|ei|越小,表示点(xi,yi)与点(xi,bxi+a)的“距离”越小,即样本数据点离直线y=bx+a的竖直距离越小。特别地,当ei=0时,表示点(xi,yi)在这条直线上.
在实际应用中,因为绝对值使得计算不方便,所以人们通常用各散点到直线的竖直距离的平方之和
求a,b的值,使Q(a,b)最小
上式是关于b的二次函数,因此要使Q取得最小值,当且仅当b的取值为
我们将 称为Y关于x的经验回归方程,也称经验回归函数或经验回归公式,其图形称为经验回归直线,这种求经验回归方程的方法叫最小二乘法.
问题5:利用下表的数据,依据用最小二乘估计一元线性回归模型参数的公式,求出儿子身高Y关于父亲身高x的经验回归方程。
问题6:当x=176时, ,如果一位父亲身高为176cm,他儿子长大后身高一定能长到177cm吗?为什么?
例如,对于右表中的第6个观测,父亲身高为172cm,其儿子身高的观测值为y==176(cm),预测值为96=0.839×172+28.957=173.265(cm),残差为176-173.265=2.735(cm).类似地,可以得到其他的残差,如右表所示.
问题7:儿子身高与父亲身高的关系,运用残差分析所得的一元线性回归模型的有效性吗?
残差图:作图时纵坐标 为残差,横坐标可以选为样本编号,或身高数据,或体重估计值等,这样作出的图形称为残差图.
观察表可以看到,残差有正有负,残差的绝对值最大是4.413.观察残差的散点图可以发现,残差比较均匀地分布在横轴的两边,说明残差比较符合一元线性回归模型的假定,是均值为0、方差为σ2的随机变量的观测值.可见,通过观察残差图可以直观判新模型是否满足一元线性回归模型的假设. 一般地,建立经验回归方程后,通常需要对模型刻画数据的效果进行分析,借助残差分析还可以对模型进行改进,使我们能根据改进模型作出更符合实际的预测与决策。
问题8:观察以下四幅残差图,你认为哪一个残差满足一元线性回归模型中对随机误差的假定?
所以,只有图(4)满足一元线性回归模型对随机误差的假设。
例1.经验表明,对于同一树种,一般树的胸径(树的主干在地面以上1.3m处的直径)越大,树就越高.由于测量树高比测量胸径困难,因此研究人员希望由胸径预测树高.在研究树高与胸径之间的关系时,某林场收集了某种树的一些数据如下表所示,试根据这些数据建立树高关于胸径的经验回归方程.
解: 以胸径为横坐标,树高为纵坐标作散点图如下:
散点大致分布在一条从左下角到右上角的直线附近,表明两个变量线性相关,并且是正相关,因此可以用一元线性回归模型刻画树高与胸径之间的关系.用d表示胸径,h表示树高,根据据最小二乘法,计算可得经验回归方程为
根据经验回归方程,由胸径的数据可以计算出树高的预测值(精确到0.1)以及相应的残差,如下表所示.
以胸径为横坐标,残差为纵坐标,作残差图,得到下图.
观察残差表和残差图,可以看到残差的绝对值最大是 0.8,所有残差分布在以横轴为对称轴、宽度小于2的带状区域内 .可见经验回归方程较好地刻画了树高与胸径的关系,我们可以根据经验回归方程由胸径预测树高.
(1)确定研究对象,明确哪个变量是解释变量,哪个变量是响应变量.(2)画出解释变量与响应变量的散点图,观察它们之间的关系 (如是否存在线性关系等).(3)由经验确定回归方程的类型.(4)按一定规则(如最小二乘法)估计经验回归方程中的参数.(5)得出结果后需进行线性回归分析.①残差平方和越小,模型的拟合效果越好.②决定系数R2取值越大,说明模型的拟合效果越好.需要注意的是:若题中给出了检验回归方程是否理想的条件,则根据题意进行分析检验即可.
建立线性回归模型的基本步骤:
例2.人们常将男子短跑100m的高水平运动员称为“百米飞人”.下表给出了1968年之前男子短跑100m世界纪录产生的年份和世界纪录的数据.试依据这些成对数据,建立男子短跑100m世界纪录关于纪录产生年份的经验回归方程。
解:以成对数据中的世界纪录产生年份为横坐标,世界纪录为纵坐标作散点图,得到下图,散点看上去大致分布在一条直线附近,似乎可用一元线性回归模型建立经验回归方程.用Y表示男子短跑100m的世界纪录,t表示纪录产生的年份 ,利用一元线性回归模型来刻画世界纪录和世界纪录产生年份之间的关系 . 根据最小二乘法,由表中的数据得到经验回归方程为:
将经验回归直线叠加到散点图,得到下图:
仔细观察:从图中可以看到,经验回归方程较好地刻画了散点的变化趋势,请再仔细观察图形,你能看出其中存在的问题吗? 第一个世界纪录所对应的散点远离经验回归直线,并且前后两时间段中的散点都在经验回归直线的上方,中间时间段的散点都在经验回归直线的下方. 这说明散点并不是随机分布在经验回归直线的周围, 而是围绕着经验回归直线有一定的变化规律, 即成对样本数据呈现出明显的非线性相关的特征.
思考:你能对模型进行修改,以使其更好地反映散点的分布特征吗?
仔细观察,可以发现散点更趋向于落在中间下凸且递减的某条曲线附近.回顾已有的函数知识,可以发现函数y=-lnx的图象具有类似的形状特征 注意到100m短跑的第一个世界纪录产生于1896年, 因此可以认为散点是集中在曲线y=f(t)=c1+c2ln(t-1895)的周围,其中c1、c2为未知参数,且c2<0. 用上述函数刻画数据变化的趋势,这是一个非线性经验回归函数,其中c1,c2是待定参数,现在问题转化为如何利用成对数据估计参数c1和c2
令x=ln(t-1895),则 Y=c2x+c1对数据进行变化可得下表:
得到散点图,由表中的数据得到经验回归方程为:
上图表明,经验回归方程对于成对数据具有非常好的拟合精度.将x=ln(t-1895)代入:
对于通过创纪录时间预报世界纪录的问题,我们建立了两个回归模型,得到了两个回归方程,你能判断哪个回归方程拟合的精度更好吗?
我们发现,散点图中各散点都非常靠近②的图象, 表明非线性经验回归方程②对于原始数据的拟合效果远远好于经验回归方程①.
(1).直接观察法.在同一坐标系中画出成对数据散点图、非线性经验回归方程②的图象(蓝色)以及经验回归方程①的图象(红色).
(2).残差分析:残差平方和越小,模型拟合效果越好.
Q2明显小于Q1,说明非线性回归方程的拟合效果要优于线性回归方程.
(3).利用决定系数R2刻画回归效果.
R2越大,表示残差平方和越小,即模型的拟合效果越好R2越小,表示残差平方和越大,即模型拟合效果越差.①和②的R2分别为0.7325和0.9983说明非线性回归方程的拟合效果要优于线性回归方程。
(4)用新的观测数据来检验模型的拟合效果,事实上,我们还有1968年之后的男子短跑100m世界纪录数据,如表所示
在散点图中,绘制表中的散点(绿色),再添加经验回归方程①所对应的经验回归直线(红色),以及经验回归方程②所对应的经验回归曲线(蓝色),得到右图.显然绿色散点分布在蓝色经验回归曲线的附近,远离红色经验回归直线,表明经验回归方程②对于新数据的预报效果远远好于①.
思考:在上述问题情境中,男子短跑100m世界纪录和纪录创建年份之间呈现出对数关系,能借助于样本相关系数刻画这种关系的强弱吗?
在使用经验回归方程进行预测时,需要注意下列问题:(1)经验回归方程只适用于所研究的样本的总体,例如,根据我国父亲身高与儿子身高的数据建立的经验回归方程,不能用来描述美国父亲身高与儿子身高之间的关系,同样,根据生长在南方多雨地区的树高与胸径的数据建立的经验回归方程,不能用来描述北方干早地区的树高与胸径之间的关系。(2)经验回归方程一般都有时效性,例如,根据20世纪80年代的父亲身高与儿子身高的数据建立的经验回归方程,不能用来描述现在的父亲身高与儿子身高之间的关系。(3)解释变量的取值不能离样本数据的范围太远,一般解释变量的取值在样本数据范围内,经验回归方程的预报效果会比较好,超出这个范围越远,预报的效果越差,(4)不能期望经验回归方程得到的预报值就是响应变量的精确值,事实上,它是响应变量的可能取值的平均值。
建立非线性经验回归模型的基本步骤:
1.确定研究对象,明确哪个是解释变量,哪个是响应变量;2.由经验确定非线性经验回归方程的模型;3.通过变换,将非线性经验回归模型转化为线性经验回归模型;4.按照公式计算经验回归方程中的参数,得到经验回归方程;5.消去新元,得到非线性经验回归方程;6.得出结果后分析残差图是否有异常 .
跟踪训练1.一只药用昆虫的产卵数y与一定范围内的温度x有关,现收集了6组观测数据列于表中:
线性回归残差的平方和:
其中 分别为观测数据中的温度和产卵数,i=1,2,3,4,5,6.
(1)若用线性回归模型拟合,求y关于x的回归方程 (精确到0.1);
(2)若用非线性回归模型拟合,求得y关于x回归方程为且相关指数R2=0.9522.
①试与(1)中的线性回归模型相比较,用R2说明哪种模型的拟合效果更好 ?②用拟合效果好的模型预测温度为35℃时该种药用昆虫的产卵数.(结果取整数). 附:相关系数
∵0.9398<0.9522
相关课件
高中数学人教A版 (2019)选择性必修 第三册8.2 一元线性回归模型及其应用优秀课件ppt: 这是一份高中数学人教A版 (2019)选择性必修 第三册8.2 一元线性回归模型及其应用优秀课件ppt,共36页。
人教A版 (2019)选择性必修 第三册8.2 一元线性回归模型及其应用公开课ppt课件: 这是一份人教A版 (2019)选择性必修 第三册8.2 一元线性回归模型及其应用公开课ppt课件,共52页。
高中人教A版 (2019)8.2 一元线性回归模型及其应用优质ppt课件: 这是一份高中人教A版 (2019)8.2 一元线性回归模型及其应用优质ppt课件,文件包含新人教A版数学选择性必修三82一元线性回归模型及其应用课件41524pptx、新人教A版数学选择性必修三82一元线性回归模型及其应用学案41524docx、新人教A版数学选择性必修三82一元线性回归模型及其应用分层练习基础练+能力练41524docx等3份课件配套教学资源,其中PPT共39页, 欢迎下载使用。












