







所属成套资源:川教版信息技术九年级上册课件PPT
初中川教版(2019)第2节 处理网络信息教学课件ppt
展开
这是一份初中川教版(2019)第2节 处理网络信息教学课件ppt,共37页。PPT课件主要包含了课堂导入,提取书籍的名称,保存信息,我的课外读物,课堂小结等内容,欢迎下载使用。
同学们: 上一节中,我们在Pythn中用requests模块获取到了“京东商城”的网页信息,接下来,根据需要对数据进行处理和保存。让我们按前面分析的步骤一步一步地来实现吧。
1. 学会使用BeautifulSup模块,对获取到的信息进行清理。
2.了解Html标签在使用BeautifulSup模块时的作用。
3.学会字符串合并、替换等简单操作。
4.掌握在Pythn中使用pen函数保存文件,了解常用编码方式UTF-8与GBK。
二、同时提取书名和好评数
使用BeautifulSup模块,可以很简单地将我们需要的内容从网页中提取出来。
解析“天猫图书”页面源代码(resTxt即网页源代码变量)的代码如下:resStr=BeautifulSup(resTxt,’lxml’)
这里,用BeautifulSup模块调用lxml解析器处理网页源代码resTxt,分析出源代码中的标签、数据等,并将处理后的结果赋值给变量resStr。
下面,使用BeautifulSup模块,提取网页中书籍的名称。用作为关键字,通过select函数来取得所有书籍的名称列表sm的代码如下:sm=resStr.select(‘[]‘)sm是所有书籍名称列表,按在网页中出现的先后顺序依次编号为0,1,2,3,4……
也可以将提取到的书籍名称直接打印,代码如下:print(resStr.select(‘class=”title”]’)
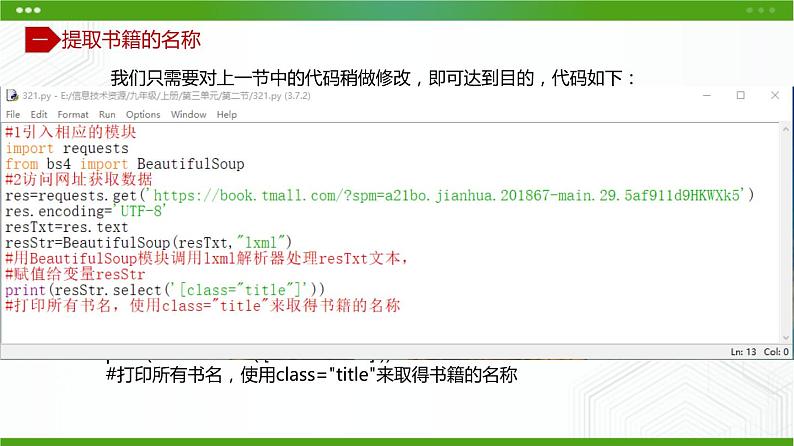
我们只需要对上一节中的代码稍做修改,即可达到目的,代码如下:#1引入相应的模块imprt requestsfrm bs4 imprt BeautifulSup#2访问网址获取数据res=requests.get('')res.encding='UTF-8'resTxt=res.textresStr=BeautifulSup(resTxt,"lxml")#用BeautifulSup模块调用lxml解析器处理resTxt文本,#赋值给变量resStrprint(resStr.select('[]'))#打印所有书名,使用来取得书籍的名称
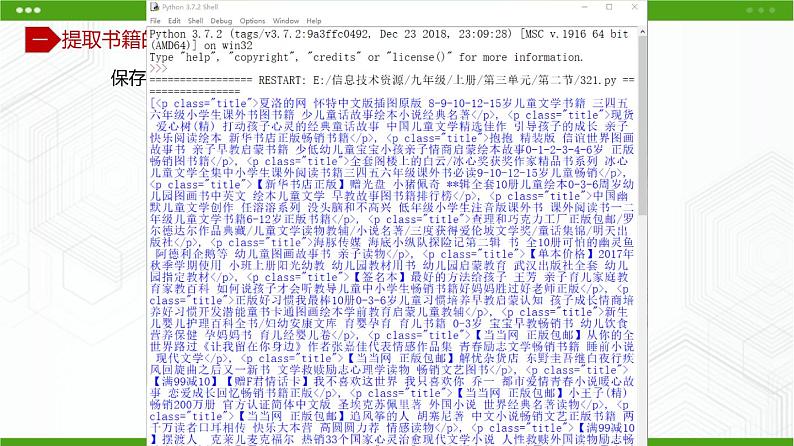
保存上面代码,运行,结果如下图所示:
上图,使用BeautifulSup模块清除掉了除书籍名称之外的所有内容,得到一个列表,列表中第0项内容是:三国演义,……,以此类推。每一项目中都有不需要的span标签,再将上面代码完善一下,用fr循环提取出列表中的每一项内容,并只打印其中的书籍名称,代码如下:#①引入相应的库imprt requestsfrm bs4 imprt BeautifulSup#②访问网址获取数据res=requests.get('')res.encding='UTF-8'resTxt=res.textresStr=BeautifulSup(resTxt,'lxml')sm=resStr.select('[]')#我们将所有获取到的书籍名称列表,赋值给变量smfr fr in sm:#在列表变量sm中循环,准备读取出每本书籍的名称 print(fr.string)#在屏幕上显示出每本书籍的名称
运行结果如下图所示:
使用BeautifulSup模块从网页中获取到需要的信息,关键在于从Html中找到所需信息的“标签”,通过标签的值,就可以将需要的信息提取出来。
拓展: 获取好评数、价格等信息与获取书籍名称的方法相同,只是关键词不同。同学们可试试修改一下上面的代码,来提取书籍的好评数、内容简介和价格。
提取书籍好评数的代码如下:#1引入相应的库imprt requestsfrm bs4 imprt BeautifulSup#2访问网址获取数据res=requests.get('')res.encding='UTF-8'resTxt=res.textresStr=BeautifulSup(resTxt,'lxml')hps=resStr.select('[]')#请与上面代码对比,这里的标签进行了修改fr fr in hps: print(fr.string)
小提示: 每种书籍的好评数后面都有“条好评”这几个文字,可以使用字符串替换的方法将文字删除,只保留数字,替换命令是replace。
请同学们运行下面代码,并观察运行结果,思考 replace命令的作用。stra="这是个苹果"print(stra.replace('苹果','桃子'))print(stra.replace('西瓜','桃子'))
不难发现第一个 replace语句将苹果替换成了桃子,而第二个语句中,因为字符串stra中没有“西瓜”,所以替换不成功,返回原字符串。
只保留好评数数字部分的代码就是:#1引入相应的库imprt requestsfrm bs4 imprt BeautifulSup#2访问网址获取数据res=requests.get('')res.encding='UTF-8'resTxt=res.textresStr=BeautifulSup(resTxt,'lxml')hps=resStr.select('[]')fr fr in hps: hpsStr=('条好评',"") .strip()#用空字符串替换“条好评”﹔ print(hpsStr)#strip()函数,清除文本头部与尾部多余空格以及分段符
前面分别提取到了书名和好评数,我们要将二者结合起来一起显示,这就要使用字符串合并的方法。
请同学们运行下面代码,仔细观察打印结果,并思考其中的+号起了什么作用?stra="欢欢"strb="圆圆"strc="太棒了!"print(stra+strc)print(stra+strb+strc)
由上面代码可以发现:使用+号,可以将两个字符串合并在一起。使用+号合并字符串在七年级上册Pythn编程时已经使用过了。用+号合并字符串时,两个字符串之间是没有间隔的。
我们已经分别提取了所有的书名列表和好评数列表,下一步要将每一本书的名称和对应的好评数合并,中间用逗号分隔。用fr循环来实现,用fr来依次枚举列表title中的每一个书名,同时增加变量i表示列表title-sub的索引号来依次获取对应的好评数,即title-sub[i],变量i从0开始,依次加1,代码如下:#1引入相应的库imprt requestsfrm bs4 imprt BeautifulSup#2访问网址获取数据res=requests.get('')res.encding='UTF--8'resTxt=res.textresStr=BeautifulSup(resTxt,'xml')sm=resStr.select('[]') #获取书籍名hps=resStr.select('[]') #获取书籍好评数i=Oi=0fr fr in sm: smStr=fr.string #提取书名 hpsStr=hps[i]("条好评","") .strip() #与当前书名对应的第i个好评数 print(smStr +',' + hpsStr) #连接书名与对应好评数字符串 i=i+l
根据前面的分析,下一步就是将这些信息保存到文件中,以便对数据进行后期处理。像上图中的数据,数据与数据之间用英文逗号来分隔,我们可以将其保存为扩展名为csv的文件,其实就是最简单的Excel文档,可以使用“Excel”或者“WPS表格”来打开它。
在Pythn中,我们通常使用pen函数来打开、保存、读取及写入文件。
请同学们编写下面代码,将该代码文件保存在Pythn目录文件夹下,然后运行它,看看会发生什么情况。fl=pen('测试文件.txt','w' ,encding="GBK")#打开一个文件,但这个文件本不存在。fl.clse() #关闭这个被打开的文件
运行程序后,什么结果都没有,再看看代码所在的文件夹呢?文件夹中出现了一个空白的文件,名字就叫“测试文件.txt”。显然,上面的代码做了一件事,那就是新建了一个空白的文件。代码中的w,是单词 write(写入)的缩写,意思是以“写入”的方式打开这个文件。文件编码方式是GBK,为默认编码方式,可以不写。如果编码方式是UTF-8,则必须指定。
现在用 write()方法试试往这个文件中写入内容,看看会发生什么情况。请同学们修改代码如下,观察“测试文件.txt”中发生了什么变化。fl=pen('测试文件.txt','w')fl.write('我是欢欢!')fl.clse()
请同学们再修改代码,往文件中写入另一句话,观察“测试文件.txt”中发生了什么变化,代码如下:fl=pen('测试文件.txt' ,'w')fl.write('我喜欢玩Pythn! ')fl.clse()
运行之后再打开“测试文件.txt”,发现了什么呢?原始文件中的内容“我是欢欢!”这句话不见了。只有“我喜欢玩Pythn!”也就是说,使用w方式打开文件,再写入内容,会覆盖掉文件中原来的内容。
请同学们再修改代码,将打开方式写入(w)换成追加(a),运行并观察“测试文件.txt”中发生了什么变化。fl=pen('测试文件.txt' ,'a')fl.write('我喜欢玩Pythn! ')fl.clse()
运行之后再打开“测试文件.txt”,发现了什么呢?有2句“我喜欢玩Pythn!”。使用a方式打开文件,再写入内容,不会覆盖原来的内容,会在后面添加新的内容。
使用pen函数打开文件,要注意打开方式的参数:读“r”、写“w”、追加“a‘”、读文件时要求文件已经存在,写或者追加时,若文件不存在可以自动创建一个新文件。写入文件时要注意,“w”方式会把原来的内容覆盖,"a”方式会把新内容加在原文末尾。
GBK编码与UTF-8编码 无论是保存文件、读取文件,还是往文件中写入内容,都要注意,文件可能会有不同的编码。中文Windws系统下,默认的文件编码是GB2312(GBK),所以程序中使用pen函数时,并没有用encding=‘编码方式’这个参数强行指定某种编码。但是从网页上去爬取数据时,网页的编码方式绝大多数都是UTF-8的,要把网页上的数据保存到电脑上时,最好就强行指定编码为GBK。否则编码不正确,会导致保存、读取或者写入的文本变成乱码。所以,通常使用pen函数将内容写入到文件时,可直接写为: 文件变量名=pen("文件名.txt","a",encding="GBK")
那么,GBK编码与UTF-8编码到底有什么区别呢?最早的电脑都是使用英文的,英文一个字母只占一个字符,为了在电脑中使用中文,我国就制定了一个名叫GB2312的编码标准。但GB2312只有常用汉字,并没有包含所有汉字。为此,又在GB2312的基础上扩展,形成了GBK编码,包含了几乎所有汉字与特殊字符。 其他国家也存在文字编码方式需要统一的问题,所以UTF-8编码产生了。如果中文网页使用了UTF-8编码,外国人访问也没有问题;如果中文网页使用了GBK编码,则外国人访问就必须下载中文字体,否则就看到乱码。所以,UTF-8是全球统一的通用编码,而GBK编码是中文环境中的一种编码,并不通用。 在我们学习Pythn编程语言时,可使用网上大量的现成模块,这些模块的作者来自于全球各地。所以,使用Pytbn编写代码时,建议大家尽量使用UTF-8的编码方式来保存自己的代码。当调用了UTF-8编码的外部模块时,可能我们编写的程序会出现一些出乎意料的问题。
前面爬虫获取到的书名和好评数的数据,可以保存为后缀名为csv的文件,数据与数据之间,使用英文逗号来分隔。代码如下:#1引入相应的库imprt requestsfrm bs4 imprt BeautifulSup#2访问网址获取数据res=requests.get('')res.encding='UTF-8'resTxt=res.textresStr=BeautifulSup(resTxt,'lxml')sm=resStr.select('[]') #获取书籍名hps=resStr.select('[]') #获取书籍好评数i=0stra='' #用两个单引号,定义了一个待写入的空字符串fr fr in sm: smStr=fr.string #提取书名 hpsStr=hps[i]('条好评','').strip() #对应好评数 strb=smStr+','+hpsStr #连接书名与对应好评数字符串 stra=stra+strb+'\n' #文本累加,并在每行尾部加入一分段符\n i=i+1#3写入数据到csv文件fl=pen('书籍数据.csv','w',encding="GBK")fl.write(stra) #使用write()方法,写入累加而成的字符串fl.clse()
运行代码即可得到“书籍数据.csv”文件,首先用记事本打开这个文件,效果如下图所示:
在上图中,每本书的价格与好评数,都被爬取并保存了下来,数据之间是用英文逗号分隔开的。再用“WPS表格”或“Excel”打开这个文件,效果如下图所示:
思考: 上面是把所有的书名和好评数依次合并在一个字符串中,最后用write()方法写入这一个字符串,请同学们想一想,能用追加的方式来做吗?上面只是获取了书名和好评数、能把书籍价格也加入表格吗?亲自动手实践一下吧。
通过前面的学习,我们可以用Pythn编写程序,在网络上获取需要的信息,并将其保存到文件中。而后根据需要对保存的数据信息进行加工和处理,提取出对我们有价值的信息。
相关课件
这是一份川教版(2019)九年级下册第2节 实践操作 实施机器人项目完美版ppt课件,共19页。PPT课件主要包含了课堂导入,课堂小结等内容,欢迎下载使用。
这是一份初中信息技术川教版(2019)九年级上册第1节 爬取网络信息课文配套ppt课件,共21页。PPT课件主要包含了课堂导入,明确任务,实现方法,课堂小结等内容,欢迎下载使用。
这是一份初中信息技术川教版(2019)九年级上册第3节 揭开物联网的面纱课文配套课件ppt,共28页。PPT课件主要包含了课堂导入,分析智能温室项目,认识物联网,课堂小结等内容,欢迎下载使用。







