








所属成套资源:全套高中信息技术学考复习必修1数据与计算教学课件
高中信息技术学考复习必修1第四章课时3编程处理图片、文本数据处理、数据可视化、大数据典型应用课件
展开
这是一份高中信息技术学考复习必修1第四章课时3编程处理图片、文本数据处理、数据可视化、大数据典型应用课件,共46页。PPT课件主要包含了☆kde密度图,☆常见的分词系统,标签云,城市心情,卡特里娜飓风路径图,答案A等内容,欢迎下载使用。
考点1利用matpltlib模块绘图1.概念:Matpltlib是一个绘图库,使用其中的pyplt子库所提供的函数可以快速绘图和设置图表的坐标轴、坐标轴刻度、图例等。2.常用绘图函数
3.Pythn中引入matpltlib的pyplt子库的方法为:imprt matpltlib.pyplt as plt4.实例:绘制正弦曲线(1)linspace函数:通过定义均匀间隔创建数值序列。需要指定间隔起始点、终止端,以及指定分隔值总数(包括起始点和终止点);最终函数返回间隔类均匀分布的数值序列。①格式:np.linspace(start,stp,num)
②参数start参数:数值范围的起始点。如果设置为0,则结果的第一个数为0,该参数必须提供。stp参数:数值范围的终止点。通常其为结果的最后一个值,但如果修改endpint=False,则结果中不包括该值。num参数(可选):控制结果中共有多少个元素。如果num=5,则输出数组个数为5。该参数可选,缺省为50。
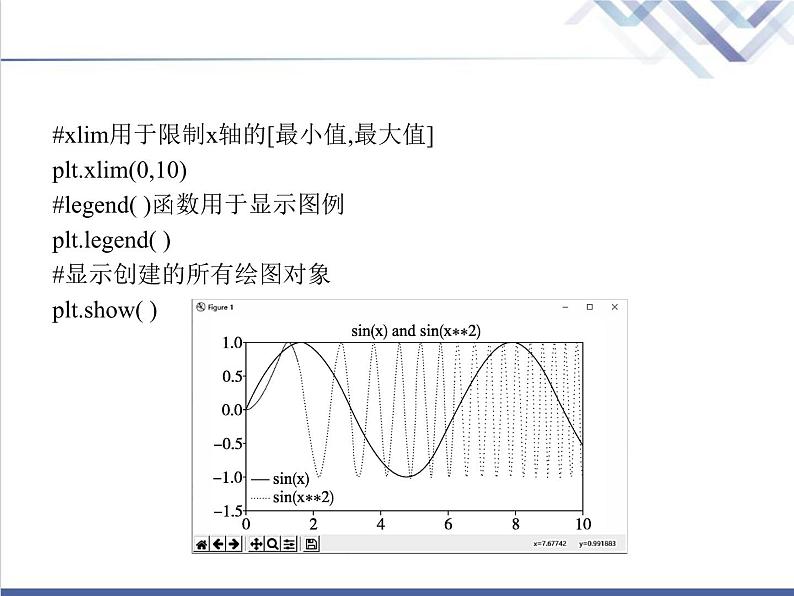
(2)实例解析“绘制正弦曲线图”#引入matpltlib绘图库中的pyplt子库并用plt代替imprt matpltlib.pyplt as plt#引入numpy科学计算模块用np代替imprt numpy as np#x轴0到10之间依照定义间隔生成均匀分布的1000个点x=np.linspace(start=0,stp=10,num=1000)#上述语句和当前省略写法等价:x=np.linspace(0,10,1000)#y1为numpy模块中的正弦函数sin(x)的值y1=np.sin(x)#y2为numpy模块中的函数sin(x * * 2)的值y2=np.sin(x * * 2)
#创建图表对象figure,figsize指定figure对象的宽和高plt.figure(figsize=(8,4))#title( )函数设置图表标题plt.title('sin(x) and sin(x * * 2)')#用x和y1绘制线形图,label标签为'sin(x)',clr颜色为红色,linewidth线宽为2plt.plt(x,y1,label='sin(x)',clr='r',linewidth=2)#用x和y2绘制散点图,marker用于指定每个点的形状(? ),c用于指定点的颜色(青色),s用于指定每个点的粗细plt.scatter(x,y2,label='sin(x * * 2)',marker=' * ',c='c',s=5)#ylim用于限制y轴的[最小值,最大值]plt.ylim(-1.5,1.5)
#xlim用于限制x轴的[最小值,最大值]plt.xlim(0,10)#legend( )函数用于显示图例plt.legend( )#显示创建的所有绘图对象plt.shw( )
典例1有如下Pythn程序段imprt matpltlib.pyplt as pltimprt numpy as npx=np.linspace(-10,10,300)y=x * * 2plt.figure(figsize=(4,4))plt.title('y=x * * 2')plt.scatter(x,y,label='x * * 2',marker='^',linewidth=1,c='c',s=5)plt.ylim(-2,20)plt.xlim(-10,10)plt.legend( )plt.shw( )
请结合上述代码回答下列问题:(1)x轴-10到10之间依照定义间隔生成均匀分布的 个点。 (2)创建的图表对象figure的宽和高分别为 英寸、 英寸。 (3)图表类型是 图。 (4)x轴的最小、最大刻度分别为 和 。 (5)该图表是否显示图例 (单选,填字母:A.显示/B.不显示)
(1) 答案 300
(2) 答案 4 4
(3) 答案 散点
(4) 答案 -10/10
(5) 答案 A
考点2利用Pythn分析数据实践1.步骤:分析数据→编制程序→查看结果2.读取外部文件的数据(1)打开与当前程序相同路径的文本文件(例如:a.txt),读取文件中的数据,文件的编码是UTF-8(如下图所示),打开的文件描述为对象f。(2)语法格式:f=pen('a.txt','r',encding='utf-8')。(3)'r'代表以只读方式打开当前文件对象,文件的指针将会放在文件的开头。这是默认模式。(4)encding用于指定当前所读文件的编码方式。(5)file.read([size]):从文件读取指定的字节数(size),若未指定或为负则读取所有。(6)file.readline([size]):读取整行,包括 ″\n″ 字符。(7)file.readlines([sizeint]):读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。(8)file.clse():关闭文件。关闭后文件不能再进行读写操作。
3.strip( )方法(1)作用:Pythn的strip()方法用于移除字符串头尾指定的字符(默认为空格)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。(2)范例:去除字符串a头尾的* 号
4.split( )方法(1)格式:字符串.split('str',num)(2)作用:通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串(3)参数? str→分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。? num→分割次数。默认为 -1,即分隔所有。(4)范例:将字符串a用空格作为分隔符切片。? a.split(' ') #第2参数num省略,分隔所有? a.split(' ',1) #第2参数num为1,在遇到第1个空格时切片,将字符串分隔为2部分。? a.split(' ',4) #第2参数num为4,字符串从左到右方向遍历,遇到空格进行切片,切片次数为4,将字符串分隔5部分。
5.实例解析“身边的百家姓”imprt pandas as pdimprt matpltlib.pyplt as plt#处理中文utf-8编码imprt cdecs#从字体管理模块引入字体属性函数(后继代码中显示中文字体处理需要)frm matpltlib.fnt_manager imprt FntPrperties#以读文件模式″r″打开中文utf-8编码的文件″names.csv″file=cdecs.pen('names.csv','r','utf-8')
#定义“复姓”列表fxfx=['欧阳','太史','端木','上官','司马','东方','独孤','南宫','万俟','闻人','夏侯','诸葛','尉迟','公羊','赫连','谵台','皇甫','宗政','濮阳','公冶','太叔','申屠','公孙','慕容','仲孙','钟离','长孙','宇文','司徒','鲜于','司空','闾丘','子车','亓官','司寇','巫马','公西','颛孙','壤驷','公良','漆雕','乐正','宰父','谷梁','拓跋','夹谷','轩辕','令狐','段干','百里','呼延','东郭','南门','羊舌','微生','公户','公玉','公仪','梁丘','公仲','公上','公门','公山','公坚','左丘','公伯','西门','公祖','第五','公乘']
#变量初始化:循环前给“姓”列表'xing'和“名”列表'ming'赋初值(空列表)xing=[ ];ming=[ ]#通过fr语句以变量line遍历打开的文件中的每一行数据(一个人的姓名)fr line in file:#取当前遍历行姓名(line)的前两个字符,判断是否是复姓列表fx的成员,是则按照复姓处理,否则按照单姓处理if line[0:2] in fx:
#复姓处理:将当前遍历的姓名line的前2个字符作为姓添加到姓列表xing,第3个字符开始剩下的字符添加到名列表mingxing.append(line[0:2])ming.append(line[2:])else:#单姓处理:将当前遍历的姓名line的第1个字符作为姓添加到姓列表xing,第2个字符开始剩下的字符添加到名列表mingxing.append(line[0:1])ming.append(line[1:])
#建立字典序列对象data,其第1元素的键为'姓',键为姓列表'xing',第2元素的键为人数'renshu',值为0(开始统计前,所有姓的个数初值皆为0)data={'xing':xing,'renshu':0}#用字典序列data构造DataFrame数据结构:两列数据,第1列列标签为字典data的第1个键'xing',该列值为姓列表xing中的值;第2列列标签为'renshu',值皆为0df=pd.DataFrame(data)#对DataFrame对象按照'xing'列的值进行分组(用grupby()函数实现)计数(用cunt( )函数实现)统计,并将统计结果(每个姓的总人数)生成新的DataFrame对象返回给变量ss=df.grupby('xing').cunt( )
#对统计结果s按照人数'renshu'进行降序排序:总人数多的姓排前面s=s.srt_values('renshu',ascending=False)#取排序后的统计结果s中前20个姓的数据,作为图表数据源绘制垂直柱形图(bar),刻度标签的旋转度数为0°(rt=0)ax=s[0:20].plt(kind='bar',rt=0)#ax为要在其上绘制的matpltlib subplt对象(subplt是将多个图画到一个平面上的工具。)#matpltlib的图表坐标轴标签不支持显示中文→用字体管理指定一个中文字体文件(simsun.ttc)来显示中文标fnt=FntPrperties(fname=r″c:\windws\fnts\simsun.ttc″,size=12)
#用fr遍历绘制的垂直柱形图的每一个x轴标签fr label in ax.get_xticklabels( ):#将当前遍历到的x轴标签label用上述语句指定的中文字体来显示label.set_fntprperties(fnt)#显示图形plt.shw( )#输出统计结果s中的前20个人数最多的姓的统计数据print(s[0:20])
6.kind参数☆bar(柱形图/直方图)
☆barh(条形图)
☆line(折线图/散布图)
【知识拓展】 用Hadp处理姓氏数据当names.csv文件数据量至GB、TB时,需采用处理静态大数据的Hadp架构,编写Map和Reduce函数处理。Map函数中统计每个分片数据中各个姓的人数,统计结果作为Reduce函数的输入,在Reduce函数中汇总每个姓的总计人数。在Hadp服务器中运行MapReduce任务,系统会自动把任务分配到各个计算机中运行。
姓氏统计的MapReduce示意图
典例2以下Pythn程序功能为:读取外部文件“选手年龄信息.csv”中每位选手的年龄,输出年龄列表中的最大值、最小值和平均值。外部文件的界面、程序界面和代码如下,请在划线处填上合适的代码。
#以读取模式打开文件f= ① #list用于存放文件中读取的当前行数据组成的列表([姓名,年龄])list1=[ ]s=0#fr 用于遍历读取文件后生成的列表f.readlines(),列表中的每个元素是从文件中读取的一行数据(姓名和年龄之间用逗号分隔)fr line in f.readlines():list=line.strip().split( ② ) #列表list1用于存放读取的年龄list1.append( ③ ) s=s+ ④ print('参赛选手年龄最大年龄为:',max(list1),'岁,最小年龄为:',min(list1),'岁,平均年龄为:',s/len(list1),'岁') ⑤ #关闭文件
答案 ①pen('选手年龄信息.csv','r') ②',' 解析 依照题意,split函数根据逗号分隔。③答案 list[1] 解析 当前行数据读取时,根据逗号将姓名和年龄分隔成列表list 1的两个元素,其中年龄对应的是第2个元素list[1]。④答案 int(list[1]) 解析 将字符串中分离的年龄用int( )转换为整型,为后面年龄的累加做好准备。⑤答案 f.clse( )
考点3文本数据处理☆地位:文本处理是大数据处理的重要分支之一。☆目的:是从大规模的文本数据中提取出符合需要的、感兴趣的和隐藏的信息。☆主要应用:搜索引擎、情报分析、自动摘要、自动校对、论文查重、文本分类、垃圾邮件过滤、机器翻译、自动应答。
1.文本数据处理的一般过程(1)准备工作:文本内容是非结构化数据,需先将文本从无结构的原始状态转化为结构化且便于计算机处理的数据。(2)典型的文本处理过程
☆中文分词①分词定义:将连续的字序列按照一定的规范重新组合成词序列的过程,就是将一个汉字序列切分成一个一个单独的词。②常用中文分词算法基于词典的分词方法基于统计的分词方法基于规则的分词方法
☆特征抽取①特征词:在中文文本分析中可以采用字、词或短语作为表示文本的特征项。多数采用词作为特征项。②特征提取:通常用分词算法和词频统计得出的结果作为特征词;通过特征提取来找出最具代表性、最有效的文本特征。③方式:据专家的知识挑选有价值的特征。
2.文本数据分析与应用(1)标签云:是文本可视化的一种方式,用词频表现文本特征,将关键词按照一定的顺序和规律排列,如频度递减、字母顺序等,并以文字大小的形式代表词语的重要性。
(2)文本情感分析:通过计算机技术对文本的主观性、观点、情绪、极性进行挖掘和分析,对文本的情感倾向做出分类判断。
典例3下列关于文本数据处理的说法错误的是( )A.文本内容是结构化数据B.标签云是文本可视化的一种方式C.中文文本分析中多数采用词作为特征项D.特征词通常是用分词算法和词频统计得出的结果
答案 A 解析 文本内容是非结构化数据。
考点4数据可视化☆概念:是将数据以图形、图像等形式表示,直接呈现数据中蕴含信息的处理过程。1.可视化的作用(1)快捷观察与追踪数据(2)实时分析数据(3)增强数据的解释力与吸引力
2.可视化的基本方法☆不同的数据类型决定了可视化的表现形式(1)时间趋势:展现随时间的推移而变化数据可采用柱形图、折线图等。(2)比例:展现各部分的大小及其占总体比例关系的数据可以采用饼图、环形图(也称面包圈图)等。(3)关系:探究具有关联性数据的分布关系,可以使用散点图、气泡图等。
用户满意度和收货天数关系图
(4)差异:探寻包含多种变量的对象与同类之间的差异和联系,可以采用雷达图。(5)空间关系:地理数据或者基于地理数据的分析结果可以运用不同颜色或图表直接在地图上进行展示。
3.可视化的工具(1)常见的数据分析软件中一般包含创建可视化图表功能。主要用于数据可视化的工具有大数据魔镜、Gephi、Tableau 等。(2)使用Pythn、R等编写程序代码实现数据的可视化。(3)可视化工具库,如基于JavaScript的D3.js、Highcharts、Ggle Charts 等,基于Pythn 的matpltlib 等。 4.可视化的典型案例数据以可视化方式展现出来,用户可以通过直观、交互的方式浏览和观察数据,发现数据中隐藏的特征、关系和模式。如“百度地图”、“百度指数”、“航班飞行实时跟踪地图”等。
典例4下列不属于数据可视化作用的是( )A.提高数据处理的智能化程度B.快捷观察与追踪数据C.实时分析数据D.增强数据的解释力与吸引力
考点5大数据典型应用☆大数据应用领域:随着大数据在各行业的应用,数据成为核心资产。目前,大数据广泛应用于金融、交通、环境、医疗、能源、农业等行业,极大地促进了各行业的发展。1.智能交通
(1)交通数据采集:GPS、卡口、视频检测、浮动车、地感线圈等产生的交通流监测数据、视频监控数据、系统数据、服务数据等构筑了交通大数据。
(2)智能交通服务智能交通主要通过交通信息服务、交通管理、公共交通、车辆控制、货运管理、电子收费、紧急救援等服务子系统为用户提供服务。其中三个子系统如下:①交通信息服务系统②交通管理系统③电子收费系统2.电子商务(1)数据来源:大型电商企业拥有大量用户数据,同时,在交易、营销、供应链、仓储、配送和售后等环节也产生了大量数据。(2)主要服务:根据电商数据,电商企业的数据平台为商户和客户提供精准营销、供应链管理、智能网站等多种数据服务
相关课件
这是一份高中信息技术学考复习必修1数据与计算第四章课时2编程处理数据教学课件,共60页。PPT课件主要包含了答案C,常用属性,常用函数等内容,欢迎下载使用。
这是一份高中信息技术学考复习必修1数据与计算第四章课时1大数据处理的基本思想与架构教学课件,共34页。PPT课件主要包含了高一各班总分平均值,热门省份Top5,学科百分比示意图,性别比例,大数据处理类型,Hadoop组成等内容,欢迎下载使用。
这是一份高中信息技术浙教版 (2019)选修3 数据管理与分析4.3 数据可视化一等奖课件ppt,文件包含423《文本数据处理与数据可视化》课件PPTpptx、423《文本数据处理与数据可视化》教案docx等2份课件配套教学资源,其中PPT共33页, 欢迎下载使用。







